[Numble 챌린지 개발일지] 2주차 협업방식 정하기, ERD 설계
컨셉 회의가 끝난 뒤 !! 백엔드 팀에서 따로 회의를 잡아 사용 기술, 컨벤션 등의 팀 규칙을 논의 했습니다.
RDBMS를 사용해야해서 다들 익숙한 MySQL을 사용하고, 클라우드는 넘블 측에서 무료 크레딧을 제공해주는 Naver Cloud를 사용하기로 했습니다.
Git으로 협업하기
사실 이전까지는 깃을 잘 활용해서 협업한 적이 없었는데, 이번에는 제대로 해보고 싶은 욕심이 있었어요👀
우선 Git으로 협업하는 방법을 알기위해서 지옥에서 온 관리자 Git 강의를 들어보았습니다..! 특히 소규모 협업 시나리오, 대규모 협업하기 파트가 굉장히 도움이 되었습니다. 게다가 무료강의에요!
https://www.youtube.com/watch?v=uA6lzRppb6E&list=PL93mKxaRDidFtXtXrRtAAL2hpp9TH6AWF&index=24
프로젝트의 규모나 특징에 따라 협업 방식을 다르게 적용하는데,
Git을 이용한 워크플로우 4가지를 소개하는 이 포스팅(https://blog.appkr.dev/learn-n-think/comparing-workflows/), 그리고 forking flow와 gitflow의 차이점을 잘 설명해주는 이 포스팅(https://devlog-h.tistory.com/6)이 어떤 워크플로우를 선택해야하는지 판단하는데에 많은 도움이 되었습니다.
각 깃 워크플로우의 특징에 대해 간략히 정리하자면 다음과 같습니다.
1. Centralized Workflow
- GIt의 특장점인 분산 버전 관리의 이점은 누리지 못한다
- SVN 개발 환경을 Git으로 전환할 때 사용하기 좋음
2. Feature Branch Workflow
- 새로운 기능을 개발할 때마다 브랜치를 만들어서 작업한다.
- 메인 코드 베이스(master)를 중심으로 해서 안전하게 새로운 기능을 개발할 수 있다.
- 따라서 지속적 통합(Continuout Integration)을 적용하기도 수월하다.
- 풀 리퀘스트를 적용하여 코드 리뷰를 할 수 있다.
풀 리퀘스트란? 기능 개발을 끝내고 master 브랜치에 바로 병합하는 것이 아니라, 브랜치를 중앙 저장소에 올리고 master에 병합해달라고 요청하는 것
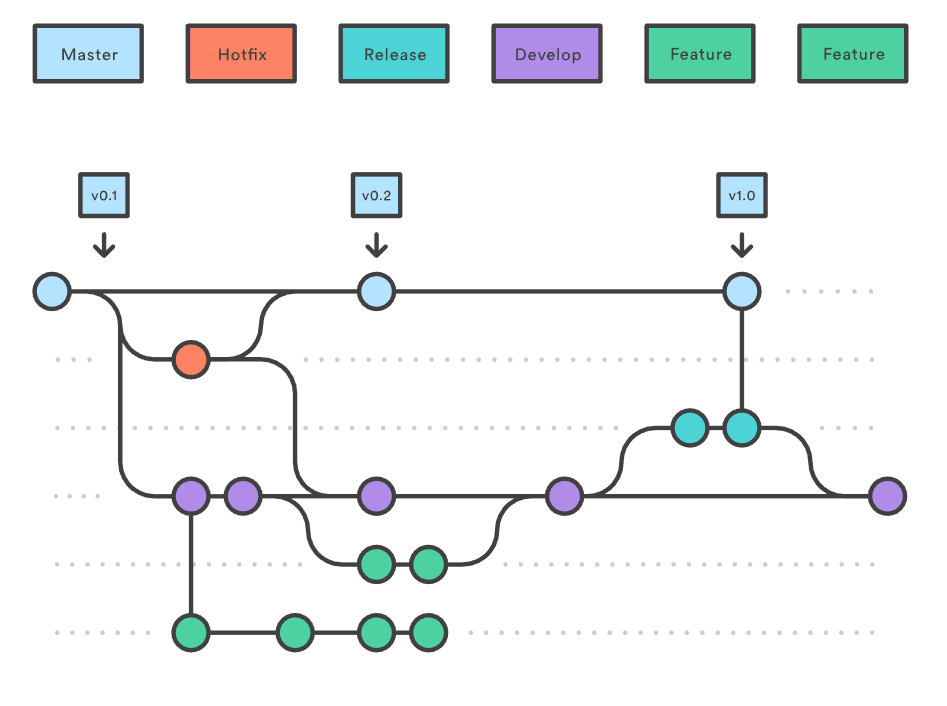
3. Gitflow Workflow
- 코드 릴리스를 중심으로 좀 더 엄격한 브랜칭 모델을 제시. 대형 프로젝트에도 적용할 수 있는 강건한 작업 절차
- 이력 관리를 위한 브랜치를 사용한다.
- feature 브랜치 -> develop 브랜치 : 기능 개발 브랜치들 병합 -> release 브랜치 -> master 브랜치: 릴리스 이력 관리(버전 태그를 부여)
- 운영 환경에 릴리스한 후 발견된 긴급 패치는 ‘hotfix’ 브랜치를 이용(다음 릴리스를 위해 개발하던 작업 내용에 전혀 영향을 주지 않는다)
- 릴리스를 위한 전용 브랜치를 사용함으로써 한 팀이 릴리스를 준비하는 동안 다른 팀은 다음 릴리스를 위한 기능 개발을 계속할 수 있다.
4. Forking Workflow
- 코드 기여자는 하나의 중앙 저장소에 푸시하는 것이 아니라 각자 자신의 원격 저장소에 푸시하고, 프로젝트 관리자만이 기여분을 공식 저장소에 병합할 수 있다.
- 프로젝트 관리자는 다른 개발자들에게 공식 저장소에 쓸 수 있는 권한을 주지 않고도 다른 개발자의 커밋을 수용할 수 있다.
- 아주 큰 규모의 분산된 팀 프로젝트에서 사용하고, 특히 오픈 소스 프로젝트에서 많이 사용하는 방식이다.
짧은 프로젝트 기간과 팀원 모두 깃을 이용한 협업에 능숙하지 않다는 점으로 미루어 보았을 때 Feature Branch Workflow가 알맞다고 판단되었습니다.
개인적으로 깃 리포지토리를 파서 해당 워크플로우를 실제로 적용해보는 연습을 했습니다 : https://github.com/ulzcq/gitflow-demo
팀원 중 한 분은 Forking Workflow를 경험해본 적이 있고, 다른 한 분도 Forking Workflow를 써보자고 제안하셨지만..! 조사한 내용에 근거하여 의견을 낸 결과, Feature Branch Workflow로 진행하기로 결정되었습니다.
제가 의견을 낸 부분이기 때문에, 최초 세팅을 하고 팀원들이 쉽게 습득할 수 있도록 관련 문서를 다음과 같이 작성했습니다. (사실 공부하면서 더 자세하게 작성한 문서도 있는데, 옵시디언에 써둔거라 나중에 블로그 포스팅으로 올려보겠습니다!)
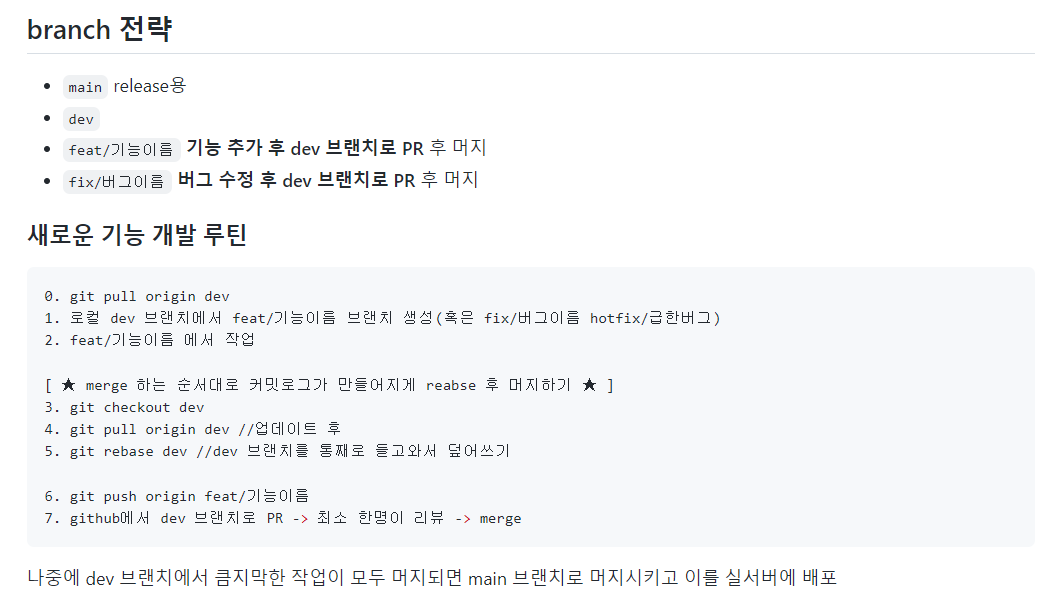
main 브랜치는 이력관리용 브랜치로 두면 좋을 것 같아서, dev 브랜치를 default 브랜치로 뒀습니다.
브랜치 이름은 'feat/기능이름' 으로 따기로 정했는데요, 빨리 작업을 쳐내고 다양한 기능을 동시에 구현해야 하다 보니 일일히 브랜치를 따서 관리하기가 쉽지 않았습니다. 그래서 종국에는 한 브랜치만 쓰게 되었는데요... 😥
그런데 나중에 프론트엔드 팀이 팀장님 의견으로, 브랜치명을 이름으로 따서 쭉 쓰시는 걸 알게되었습니다. 빨리 결과를 내야하는 경우는 이 편이 나을 수 있구나 싶긴해요. 물론 장기적으로 봤을 때도 그렇고 기능을 개발할 때마다 브랜치를 새로 따서 하는게 확실하고 좋은 방법이지만요.
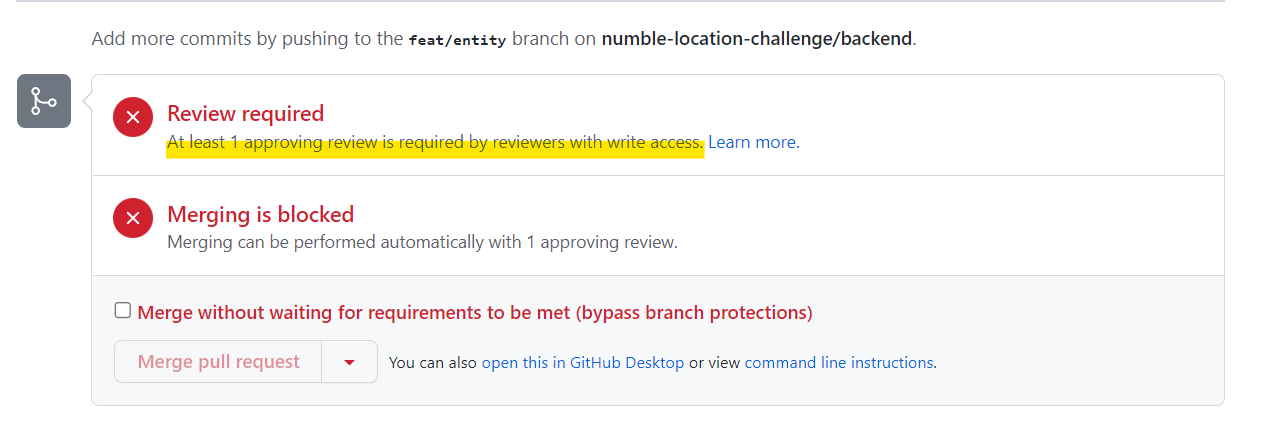
최소한의 안전장치로 한명 이상이 PR을 확인해야 머지가 가능하도록 세팅해놨어요 !
주의 사항등은 이것저것 조사해보며 적어보았는데요. GItflow workflow에 대한 내용이긴 하지만 배달의 민족 기술 블로그 포스팅 도 참고했습니다.

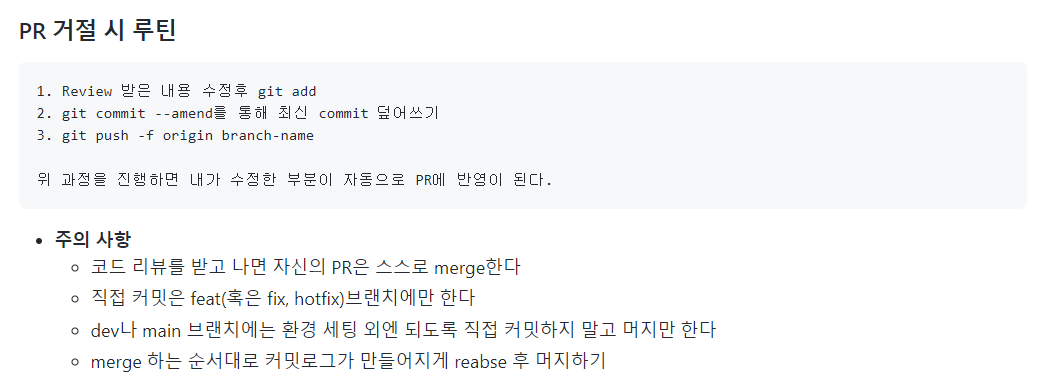
그런데 왜 자신의 PR을 스스로 머지 하는게 좋을까요? 처음에는 그냥 그게 좋은가보다 싶었는데
실제로 적용해보며 깨달은 점은 PR을 승인받더라도 이후 머지하기 직전에 수정해야하는 것을 발견할 수도 있기 때문인 것 같습니다. (개인적인 의견입니다!)
뒤늦게 깃 이슈도 써보려고 애쓰긴 했는데...! 커밋과 제대로 연결해서 사용하진 않았고, 코드리뷰도 시간이 없어서 초반 이후에는 주고받지 못했습니다 😭
다소 아쉬워서 다음엔 이 부분들을 보완하거나 경험해보고 싶습니다 !!
위 내용을 포함해 협의된 내용은 다음 문서에 정리되어 있습니다.
팀 규칙 및 컨벤션
[Numble] 나만의 지역 커뮤니티 만들기 백엔드 코드 입니다. Contribute to numble-location-challenge/backend development by creating an account on GitHub.
github.com
merge 할 때 rebase를 꼭 하자
다른 사람의 커밋뒤에 이어서 자신의 기능 브랜치를 머지하고 싶은 경우, rebase는 필수!!! 입니다. 개발 루틴에도 제가 명시해두었어요.
왜냐.. merge 이력은 branch checkout 순서에 영향을 받기 때문입니다. 따라서 rebase를 하지않으면 커밋 그래프가 뒤죽박죽 더러워집니다.
rebase를 하고 머지하면 다음과 같이 머지한 순서대로 깔끔하게 커밋 그래프가 그려지는데요.
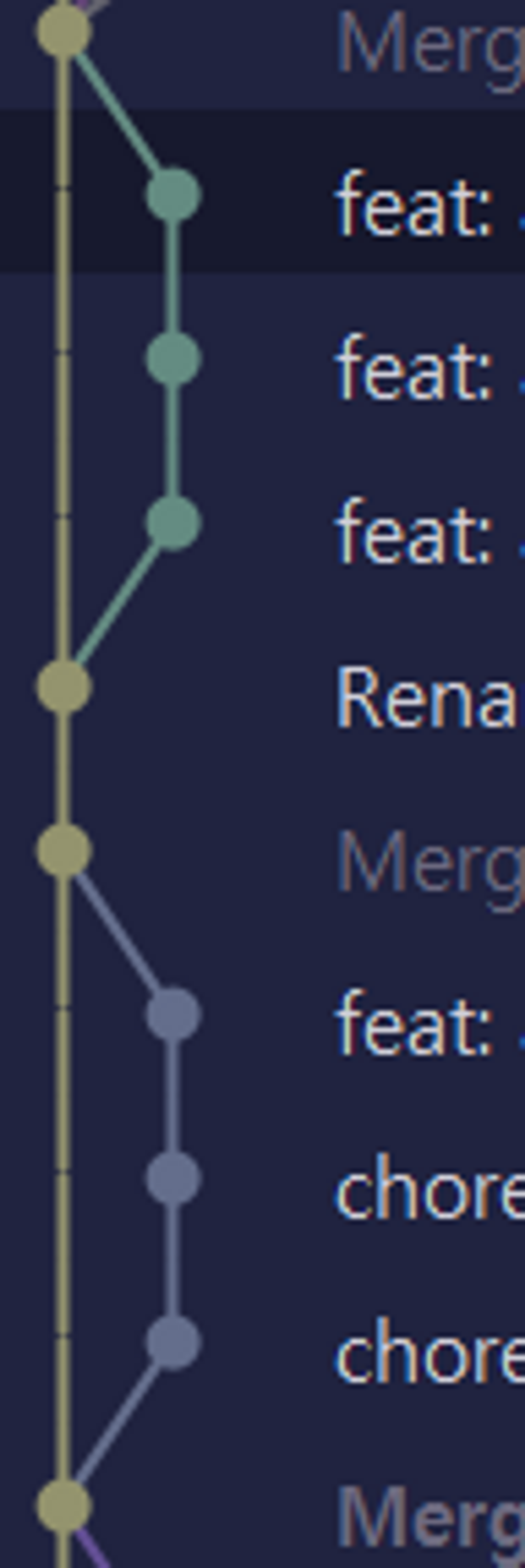
프로젝트 진행 초반에, 팀원 한 분이 rebase를 하지 않고 제 커밋뒤에 머지를 해버렸습니다. 어떤 일이 일어났을까요...
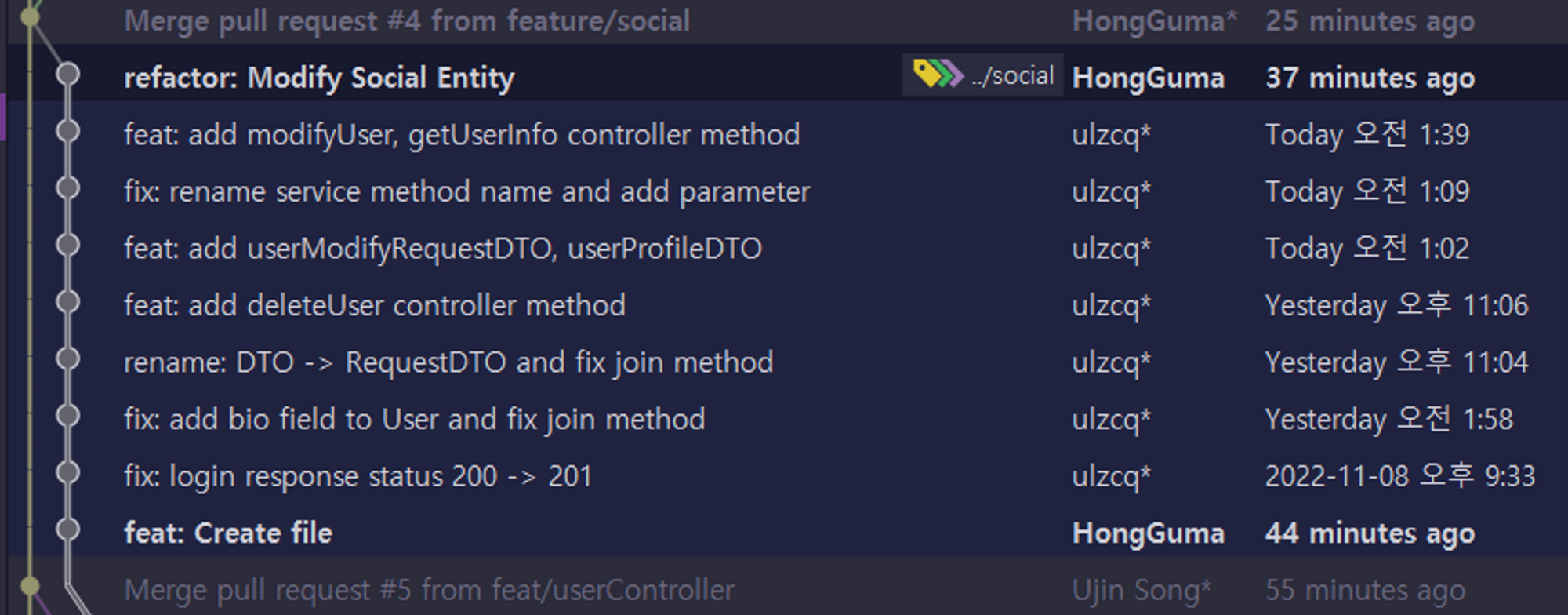
사진처럼 첫번째 rebase는 잘 적용되어서 깔끔하게 커밋이 들어 갔으나
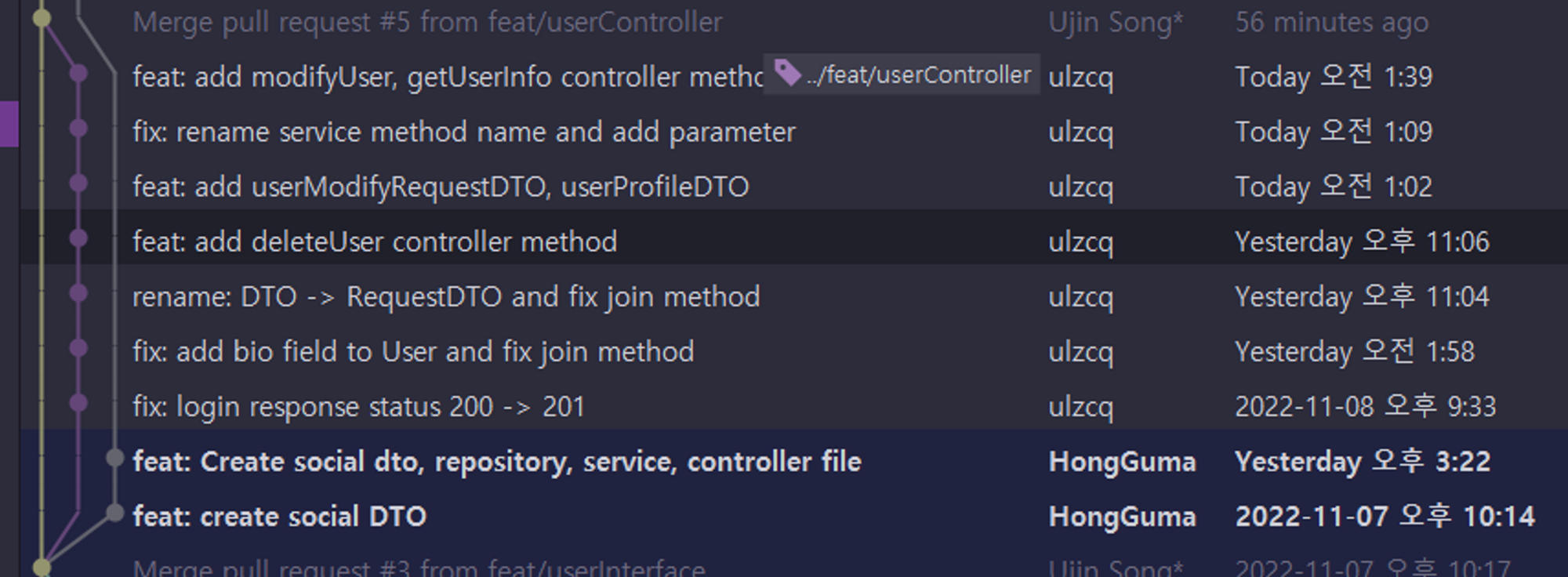
이번에는 rebase를 하지 않고 머지하여 commit이 안예쁘게 뒤죽박죽 되었습니다.
PR을 받았을 때 이걸 보고 멈췄어야 했는데… 이게 뭐꼬...하고 그대로...머지😅
결과가 깃헙에 그대로 반영이 되었고 Revert 해도 되돌려지지 않았어요 😂
급한지라 제일 최신으로 동기화 되어있는 제 로컬 dev 브랜치를 강제적으로 push해서 commit을 정리해버렸습니다..
아쉬웠던 점.... 이 포스팅을 참고해서 해결을 시도해볼 걸 그랬어요 https://nochoco-lee.tistory.com/77
rebase에 대해 잘 정리된 포스팅의 링크도 여기 있어요 https://ansohxxn.github.io/git/merge/
그래도 다음부터 rebase는 꼭 빼먹지 않고 다들 하게 되었으니.. 좋은 경험이었습니다!
Git stash, pop
이번 프로젝트를 진행하면서 새로 알게된 깃 명령어가 있는데요. 바로 stash와 pop입니다. 😉
개발하는 도중에 이전 커밋을 수정하고 싶어서 rebase 할 때, 아직 커밋되지 않았는데 수정된 코드가 있으면 에러가 나서 불가능합니다.
이때 유용하게 쓸 수 있는게 stash인데요. git stash 명령어를 사용하면 나중에 불러올 수 있도록 수정된 코드들을 임시로 저장해두고 현재 시점에서는 뿅 사라집니다 ! 그러면 rebase 도 할 수 있고 이후에 pop으로 다시 복원할 수 있어요.
DB 및 ERD 설계
백엔드 개발 요구사항을 정리한 문서 링크 입니다 :
요구사항 정리
[Numble] 나만의 지역 커뮤니티 만들기 백엔드 코드 입니다. Contribute to numble-location-challenge/backend development by creating an account on GitHub.
github.com
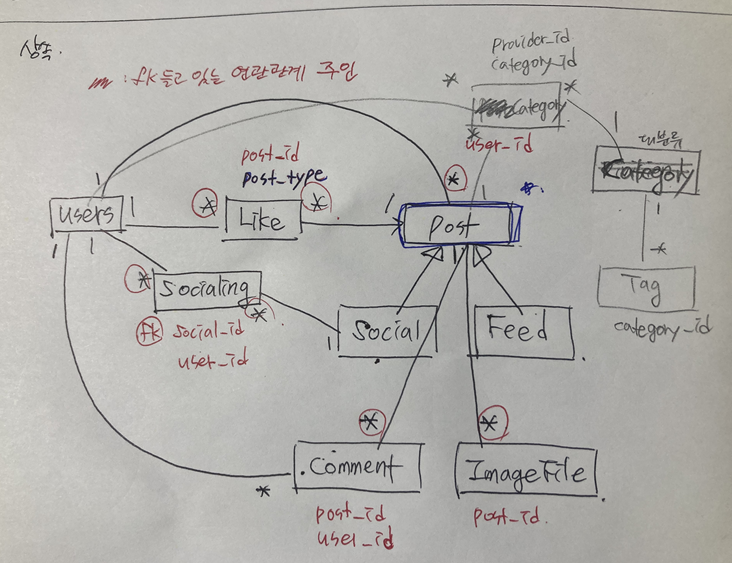
다소 복잡한? 처음 해본 설계를 꼽아보자면... 게시글 관련 엔티티를 상속관계 매핑 전략을 사용해본 점을 들 수 있겠습니다.
요구사항의 게시글에는 모임 게시글과 피드용 게시글 두 가지가 있습니다. 둘 다 좋아요 기능이 있기 때문에 어떤 쪽이든 Like와 N대1로 연결해야 합니다(Like*---1Social ,Feed). Like 테이블을 구현하는 방식은 다음 두 가지 방법을 생각해봤는데요...
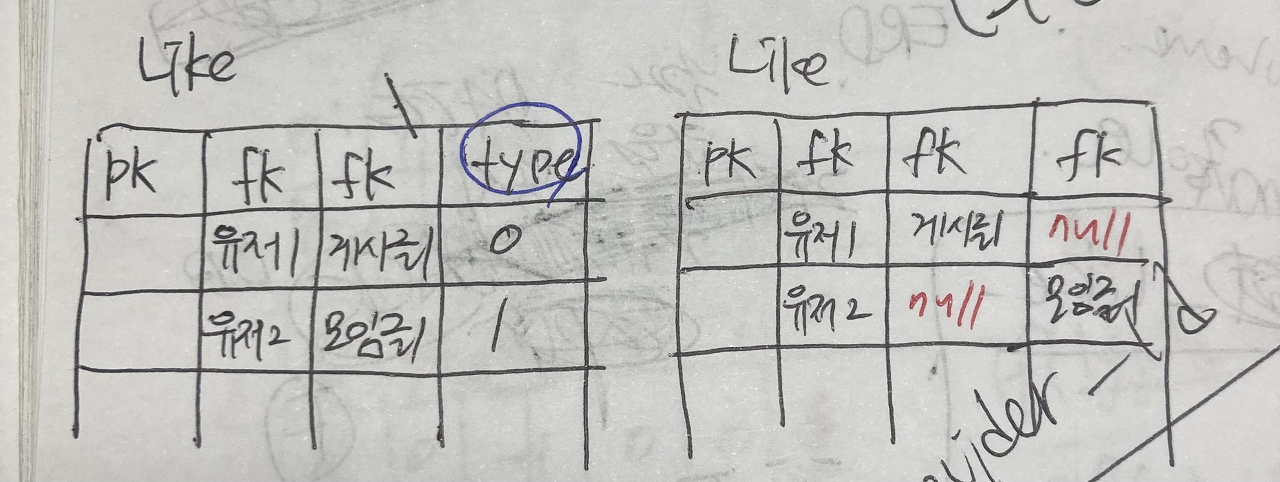
음... N대1로 연결하면 null이 들어가서 마음에 안들었는데.. 엔티티 상속으로 풀 수 있을 것 같다는 팀원 분의 의견을 듣고 한번 찾아봤습니다 ...! 👀
관계형 데이터베이스는 상속 관계 라는게 없는데요, 슈퍼타입 서브타입 관계가 비슷해서 이 방법을 사용해서 매핑 할 수 있습니다. 이 포스팅을 참고해서 다음과 같이 정리해보았는데요.
JPA에서는 @Inheritance(strategy=InheritanceType.XXX) 애노테이션을 사용해서 매핑할 수 있는데, strategy의 default 값은 SINGLE_TABLE입니다. 테이블 전략 옵션은 다음 종류가 있습니다.
- JOINED (조인 전략) : 가장 정규화 된 방법으로 구현하는 방식. 공통 필드가 슈퍼타입 테이블에만 저장되고, 서브타입 테이블에는 각자의 필드만 저장
- 하이버네이트에서는 @DiscriminatorColumn을 선언해서 DTYPE 컬럼을 수동 생성해줘야한다.
- SINGLE_TABLE(단일 테이블 전략) : 한 테이블에 다 저장하고, DTYPE으로 구분
- 서비스 규모가 크지 않고, 굳이 조인 전략을 선택해서 복잡하게 갈 필요가 없다고 판단 될 때 사용
- TABLE_PER_CLASS : 서브타입 테이블로 변환하는 구현 클래스마다 테이블을 생성
- 조인 전략과 유사하지만, 슈퍼 타입의 컬럼들을 서브 타입으로 내린다. 공통필드가 중복되도록 허용된다.
- @Id의 GenerationType.IDETITY와 같이 사용할 경우 에러가 발생할 수 있다.
@Id의 GenerationType.IDETITY를 사용할 거고, 서비스 확장성을 고려해서 조인 전략으로 설계하기로 결정했습니다. 하위 테이블인 social과 feed은 post_id를 pk 및 fk로 가지게 됩니다.
그럼 Like와 Post가 N대1로 연결되서 Social, Feed 각자가 깔끔하게 처리가 됩니다 ㅎㅎ
그리고 해시태그로 검색하는 기능이 있기 때문에 따로 Tag테이블을 뒀습니다.
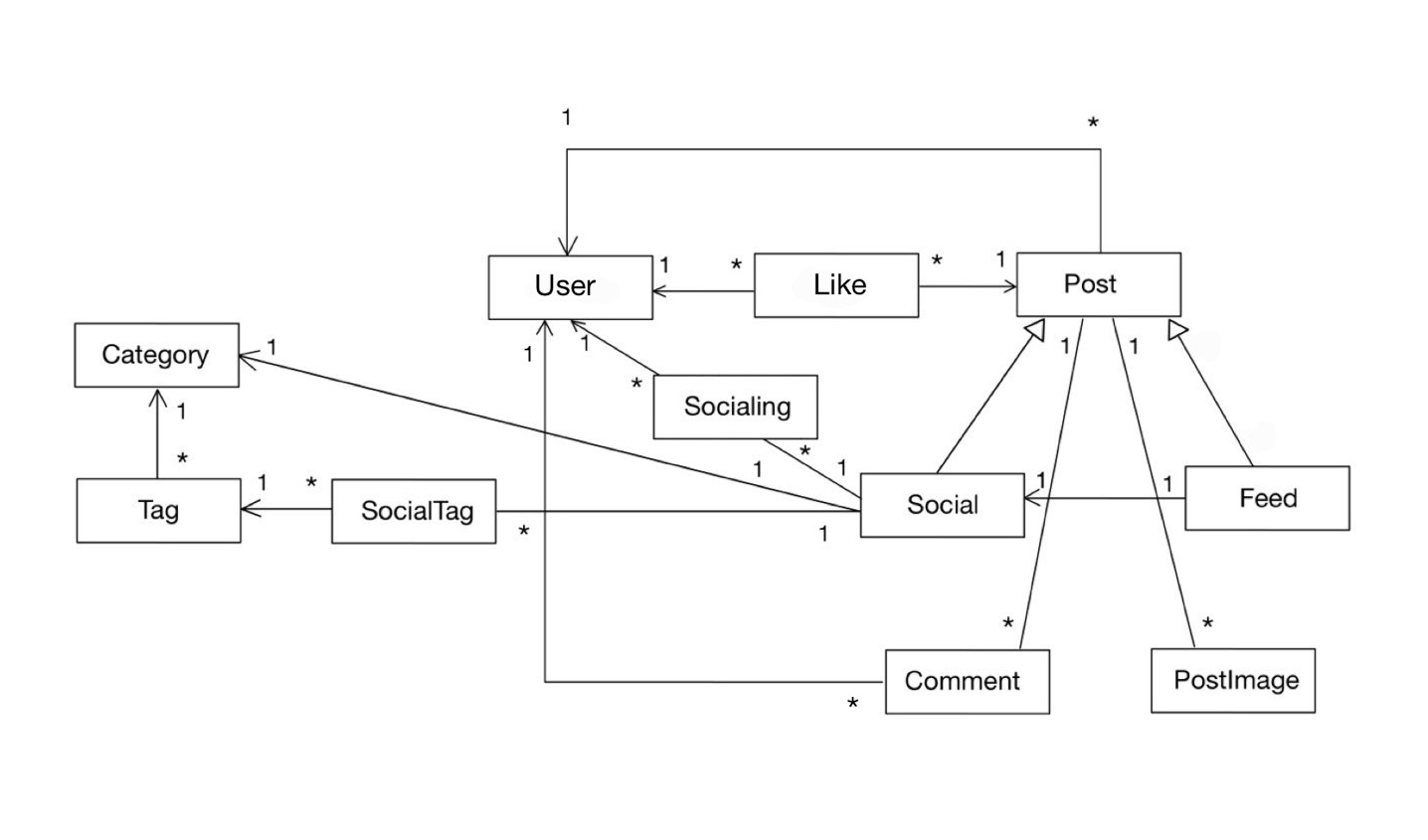
ERD
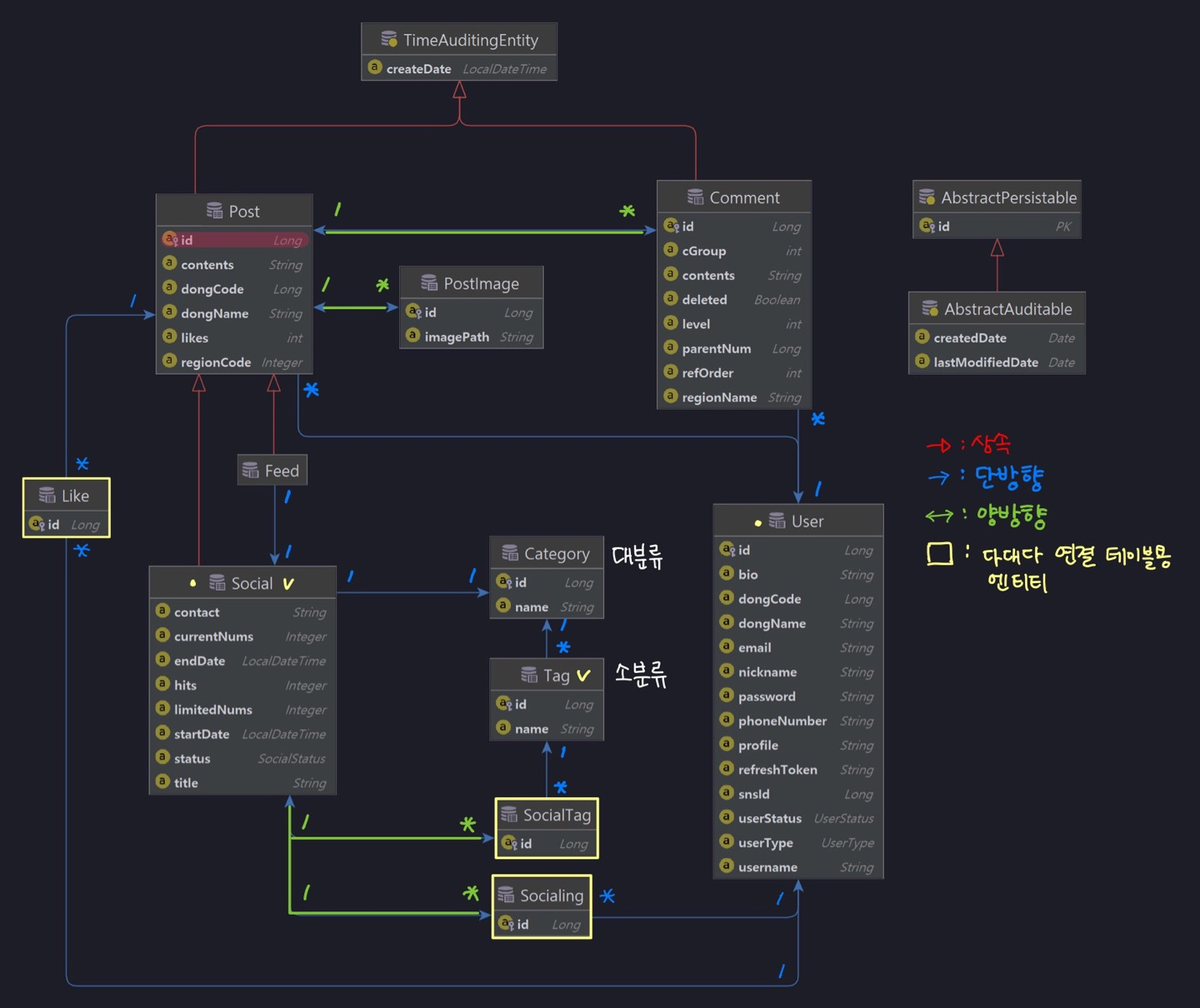
Database Table
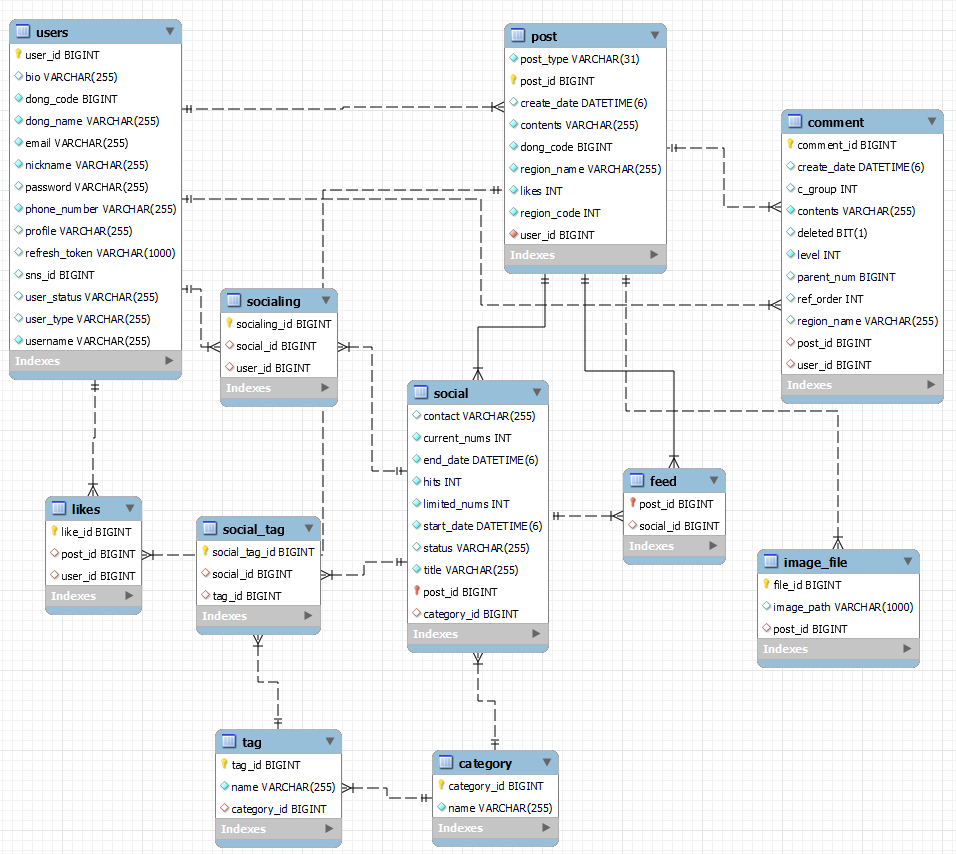
※ 주의할 점 !! USER와 LIKE는 MySQL의 예약어이므로 S를 붙여서 써야합니다!
시간이 없어 미처 달라진 이름을 수정 못했는데..💦 PostImage 엔티티는 ImageFile 테이블과 매핑된 것입니다.
<User 기준>
- User 1<--* Like *--> Post (다대다 연결 테이블)
- User 1<--* Socialing *---1 Social (다대다 연결 테이블)
- User 1<--* Post
- User 1<--* Comment
<Post 기준>
- Post ◁-- Social, Feed (상속관계)
- Post *-->1 User
- Post 1---* PostImage
- Post 1---* Comment
- Post 1<--* Like
<Social 기준>
- Social 1-->1 Category (모임은 한 개의 대분류 카테고리를 가지며, 3개의 소분류 태그를 가질 수 있다, 주 테이블인 Social에 연관관계를 설정했음)
- Social 1---* SocialTag *-->1 Tag (Social과 Tag는 다대다 관계 이므로 연결 테이블을 만듬)
- Social 1---* Socialing *-->1 User ( " )
- Social 1<--1 Feed (피드 게시글 작성 시 내가 참여 중인 모임 1개의 링크를 올릴 수 있음)
<Tag - Category>
- Tag *-->1 Category (태그(소분류)는 한 개의 카테고리(대분류)에 속한다)
처음 설계 시에 요구사항이 제대로 명시되지 않았거나 헷갈리는 부분을 양방향으로 걸었더니 나중에 난처해졌는데요...ㅠ
특히 N --> 1 단방향은 되는데 1---> N 단방향은 지양하는게 좋으므로 양방향을 걸어야한다는 점 때문에 많이 헷갈렸어요. 이 경우는 밑줄로 표시했습니다.
1대다 단방향으로 설계할 경우 다음과 같은 문제점이 있습니다.
- 엔티티가 관리하는 외래 키가 다른 테이블에 있음
- 연관관계 관리를 위해 추가로 UPDATE SQL 실행됨(성능↓).
- 1쪽의 List가 바뀌면 다(*)쪽 테이블에 update 쿼리가 나감
김영한 강사님 말씀처럼 헷갈릴 때는 단방향으로 우선 걸어두고, 필요할 때 양방향으로 걸어야한다는 걸 뼈저리게 느꼈습니다 😂😂😂